
Proxmox VE 统一了您的计算和存储系统,也就是说,您可以使用集群内的相同物理节点进行计算(处理虚拟机和容器)和复制存储。传统的计算和存储资源孤岛可以打包到单个超融合设备中。单独的存储网络 (SAN) 和通过网络附加存储 (NAS) 的连接消失了。通过集成开源软件定义存储平台 Ceph,Proxmox VE 能够直接在虚拟机管理程序节点上运行和管理 Ceph 存储。
Ceph 是一个分布式对象存储和文件系统,旨在提供卓越的性能、可靠性和可扩展性。
-
通过 CLI 和 GUI 轻松设置和管理
-
精简配置
-
快照支持
-
自愈
-
可扩展到艾字节级别
-
设置具有不同性能和冗余特性的池
-
数据被复制,使其具有容错能力
-
在商用硬件上运行
-
无需硬件 RAID 控制器
-
开源
对于中小型部署,可以直接在 Proxmox VE 集群节点上安装用于 RADOS 块设备 (RBD) 的 Ceph 服务器(请参阅 Ceph RADOS 块设备 (RBD))。最新的硬件具有大量的 CPU 能力和 RAM,因此可以在同一节点上运行存储服务和虚拟机。
为了简化管理,我们提供了pveceph – 一个用于在 Proxmox VE 节点上安装和管理Ceph服务的工具。
-
Ceph 监视器 (ceph-mon)
-
Ceph 管理器 (ceph-mgr)
-
Ceph OSD(ceph-osd;对象存储守护进程)
8.1. 前提
要构建超融合 Proxmox + Ceph 集群,您必须使用至少三台(最好是)相同的服务器进行设置。
另请查看Ceph 网站上的建议 。
高 CPU 核心频率可减少延迟,应该是首选。作为一个简单的经验法则,您应该为每个 Ceph 服务分配一个 CPU 核心(或线程),以便为稳定且持久的 Ceph 性能提供足够的资源。
特别是在超融合设置中,需要仔细监控内存消耗。除了预测虚拟机和容器的内存使用情况外,您还必须考虑有足够的内存可供 Ceph 使用,以提供出色且稳定的性能。
根据经验,对于大约1 TiB 的数据, OSD 将使用1 GiB 的内存。特别是在恢复、重新平衡或回填期间。
守护进程本身将使用额外的内存。默认情况下,守护程序的 Bluestore 后端需要3-5 GiB 内存(可调整)。相比之下,传统的 Filestore 后端使用操作系统页面缓存,内存消耗通常与 OSD 守护程序的 PG 相关。
我们建议网络带宽至少为 10 GbE 或更高,专门用于 Ceph。 如果没有可用的 10 GbE 交换机,也可以选择网状网络设置 [ 17 ] 。
流量,尤其是在恢复期间,会干扰同一网络上的其他服务,甚至可能破坏 Proxmox VE 集群堆栈。
此外,您应该估计您的带宽需求。虽然一个 HDD 可能不会使 1 Gb 链路饱和,但每个节点的多个 HDD OSD 可以,现代 NVMe SSD 甚至会快速使 10 Gbps 带宽饱和。部署具有更多带宽的网络将确保这不是您的瓶颈,而且不会很快成为瓶颈。25、40 甚至 100 Gbps 都是可能的。
在规划 Ceph 集群的大小时,考虑恢复时间非常重要。特别是对于小型集群,恢复可能需要很长时间。建议您在小型设置中使用 SSD 而不是 HDD,以缩短恢复时间,从而最大限度地减少恢复过程中发生后续故障事件的可能性。
一般来说,SSD 会比旋转磁盘提供更多的 IOPS。考虑到这一点,除了较高的成本之外,实现 基于类的池分离可能是有意义的。另一种加速 OSD 的方法是使用更快的磁盘作为日志或 DB/ W rite- A head- Log设备,请参阅 创建 Ceph OSD。如果多个 OSD 使用更快的磁盘,则必须在 OSD 和 WAL/DB(或日志)磁盘之间选择适当的平衡,否则更快的磁盘将成为所有链接的 OSD 的瓶颈。
除了磁盘类型之外,Ceph 在每个节点的磁盘大小和分布数量均匀的情况下表现最佳。例如,每个节点内的 4 x 500 GB 磁盘优于单个 1 TB 磁盘和三个 250 GB 磁盘的混合设置。
您还需要平衡 OSD 数量和单个 OSD 容量。更多容量可以提高存储密度,但这也意味着单个 OSD 故障会迫使 Ceph 立即恢复更多数据。
由于 Ceph 自行处理数据对象冗余和多个并行写入磁盘 (OSD),因此使用 RAID 控制器通常不会提高性能或可用性。相反,Ceph 被设计为自行处理整个磁盘,中间没有任何抽象。RAID 控制器不是为 Ceph 工作负载设计的,可能会使事情变得复杂,有时甚至会降低性能,因为它们的写入和缓存算法可能会干扰 Ceph 的算法。
 |
避免使用 RAID 控制器。请改用主机总线适配器 (HBA)。 |
 |
上述建议应被视为选择硬件的粗略指导。因此,使其适应您的特定需求仍然很重要。您应该测试您的设置并持续监控运行状况和性能。 |
8.2. 初始 Ceph 安装和配置
8.2.1. 使用基于 Web 的向导
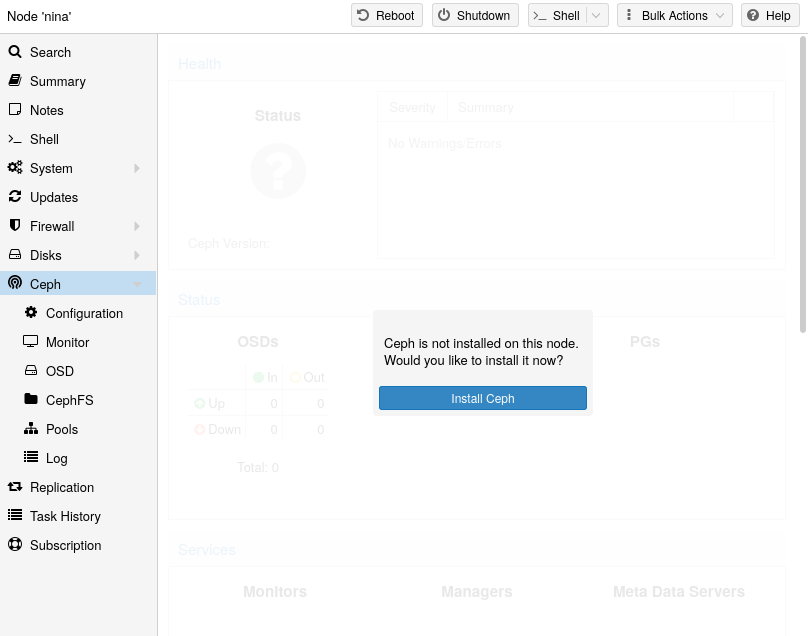
借助 Proxmox VE,您可以享受易于使用的 Ceph 安装向导。单击集群节点之一并导航到菜单树中的 Ceph 部分。如果 Ceph 尚未安装,您将看到提示进行安装。
该向导分为多个部分,每个部分都需要成功完成才能使用 Ceph。
首先,您需要选择要安装的 Ceph 版本。首选其他节点中的节点,或者如果这是您安装 Ceph 的第一个节点,则选择最新的节点。
开始安装后,向导将从 Proxmox VE 的 Ceph 存储库下载并安装所有必需的软件包。
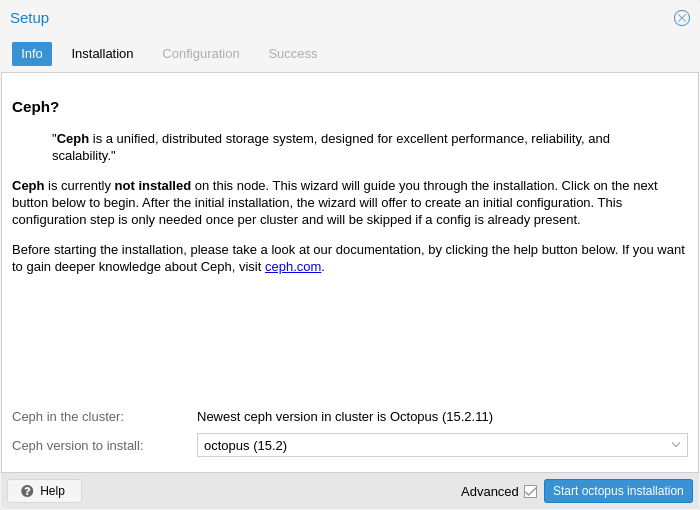
完成安装步骤后,您将需要创建配置。每个集群只需执行一次此步骤,因为此配置会通过 Proxmox VE 的集群配置 文件系统 (pmxcfs)自动分发到所有剩余集群成员。
配置步骤包括以下设置:
-
公共网络:您可以为Ceph设置专用网络。此设置是必需的。强烈建议分离 Ceph 流量。否则,可能会导致其他依赖于延迟的服务出现问题,例如,集群通信可能会降低 Ceph 的性能。
-
集群网络:作为可选步骤,您还可以进一步分离OSD复制和心跳流量。这将减轻公共网络的压力,并可能导致性能显着提高,尤其是在大型集群中。
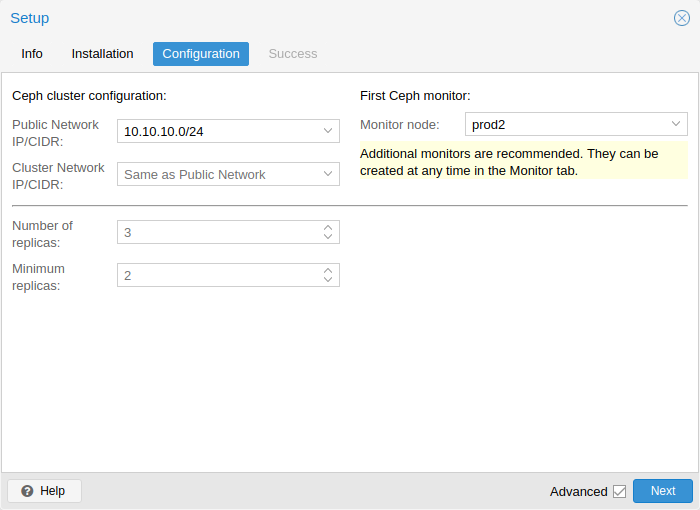
您还有两个被认为是高级的选项,因此只有在您知道自己在做什么的情况下才应该更改。
-
副本数量:定义复制对象的频率
-
最小副本数:定义将 I/O 标记为完成所需的最小副本数。
此外,您需要选择第一个监控节点。此步骤是必需的。
本章的其余部分将指导您充分利用基于 Proxmox VE 的 Ceph 设置。这包括前面提到的技巧以及更多内容,例如CephFS,它是对新 Ceph 集群的有用补充。
8.2.2. Ceph 软件包的 CLI 安装
除了 Web 界面中提供的推荐 Proxmox VE Ceph 安装向导之外,您还可以在每个节点上使用以下 CLI 命令:
pveceph安装
这会在/etc/apt/sources.list.d/ceph.list中设置apt软件包存储库 并安装所需的软件。
8.2.3. 通过 CLI 进行初始 Ceph 配置
使用 Proxmox VE Ceph 安装向导(推荐)或在一个节点上运行以下命令:
pveceph init --网络10.10 。10.0 / 24
这会在/etc/pve/ceph.conf中创建带有 Ceph 专用网络的初始配置。该文件会使用pmxcfs自动分发到所有 Proxmox VE 节点。该命令还在/etc/ceph/ceph.conf处创建一个指向该文件的符号链接。因此,您可以简单地运行 Ceph 命令,而无需指定配置文件。
8.3. Ceph 监控器
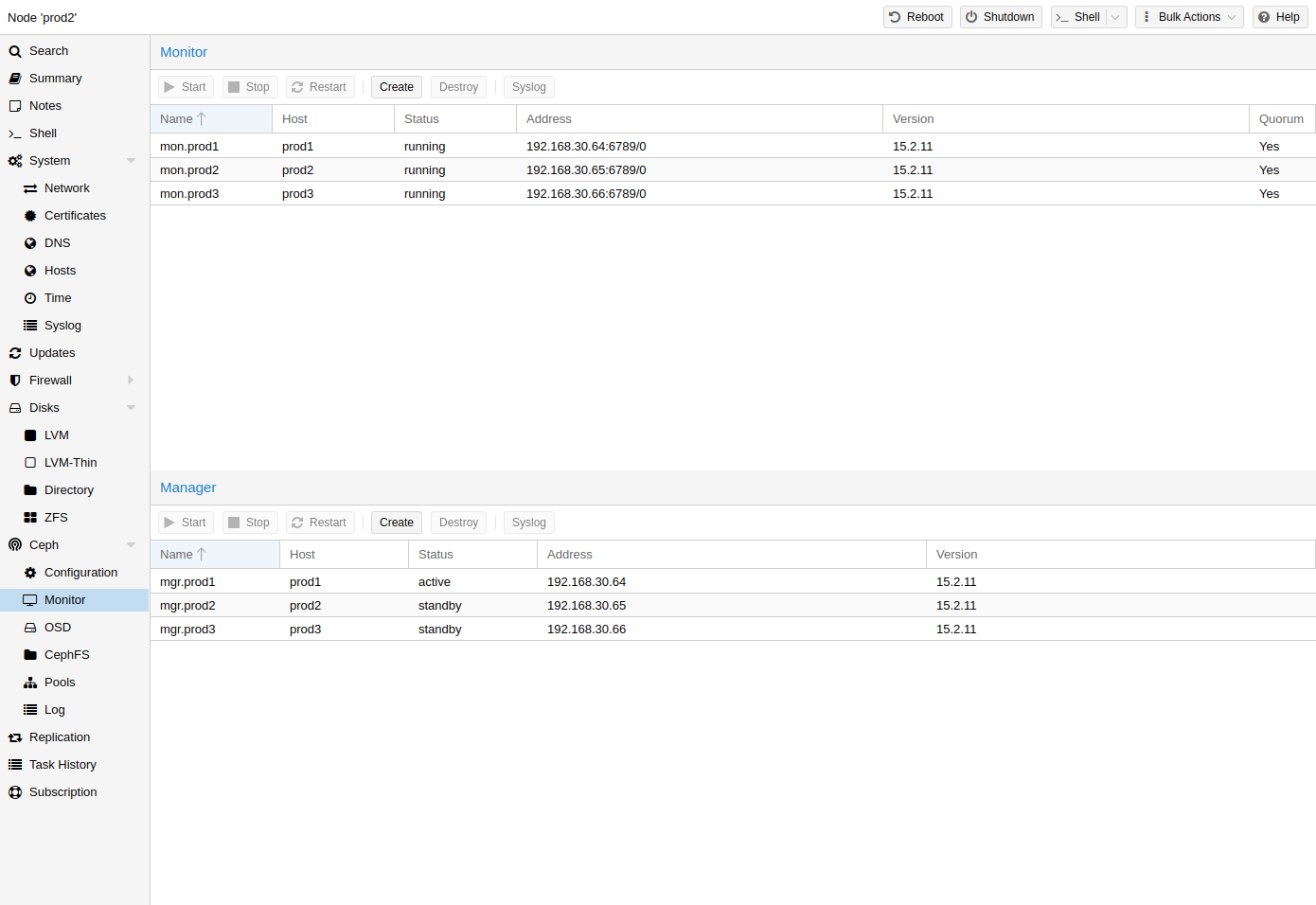
Ceph Monitor (MON) [ 18 ] 维护集群映射的主副本。为了获得高可用性,您至少需要 3 台显示器。如果您使用安装向导,则已经安装了一台显示器。只要您的集群是中小型,您就不需要超过 3 个显示器。只有非常大的集群才会需要更多。
8.3.1. 创建监视器
在要放置监视器的每个节点上(建议使用三个监视器),使用GUI 中的Ceph → Monitor选项卡创建一个监视器或运行:
pveceph mon 创建
8.3.2. 摧毁监视器
要通过 GUI 删除 Ceph Monitor,首先在树视图中选择一个节点,然后转到Ceph → Monitor面板。选择 MON 并单击“销毁” 按钮。
要通过 CLI 删除 Ceph Monitor,请首先连接到运行 MON 的节点。然后执行以下命令:
pveceph mon 毁灭
|
至少需要三台监视器才能达到法定人数。 |
8.4. Ceph 经理
Manager 守护进程与监视器一起运行。它提供了一个监控集群的接口。自 Ceph luminous 发布以来,至少 需要一个 ceph-mgr [ 19 ]守护进程。
8.4.1. 创建管理器
可以安装多个管理器,但在任何给定时间只有一个管理器处于活动状态。
pveceph mgr 创建
|
建议在监控节点上安装Ceph Manager。为了获得高可用性,请安装多个管理器。 |
8.4.2. 销毁管理器
要通过 GUI 删除 Ceph Manager,首先在树视图中选择一个节点,然后转到Ceph → Monitor面板。选择管理器并单击 销毁按钮。
要通过 CLI 删除 Ceph Monitor,请首先连接到运行 Manager 的节点。然后执行以下命令:
pveceph mgr 销毁
|
虽然管理器不是硬依赖项,但它对于 Ceph 集群至关重要,因为它处理 PG 自动缩放、设备运行状况监控、遥测等重要功能。 |
8.5。Ceph OSD
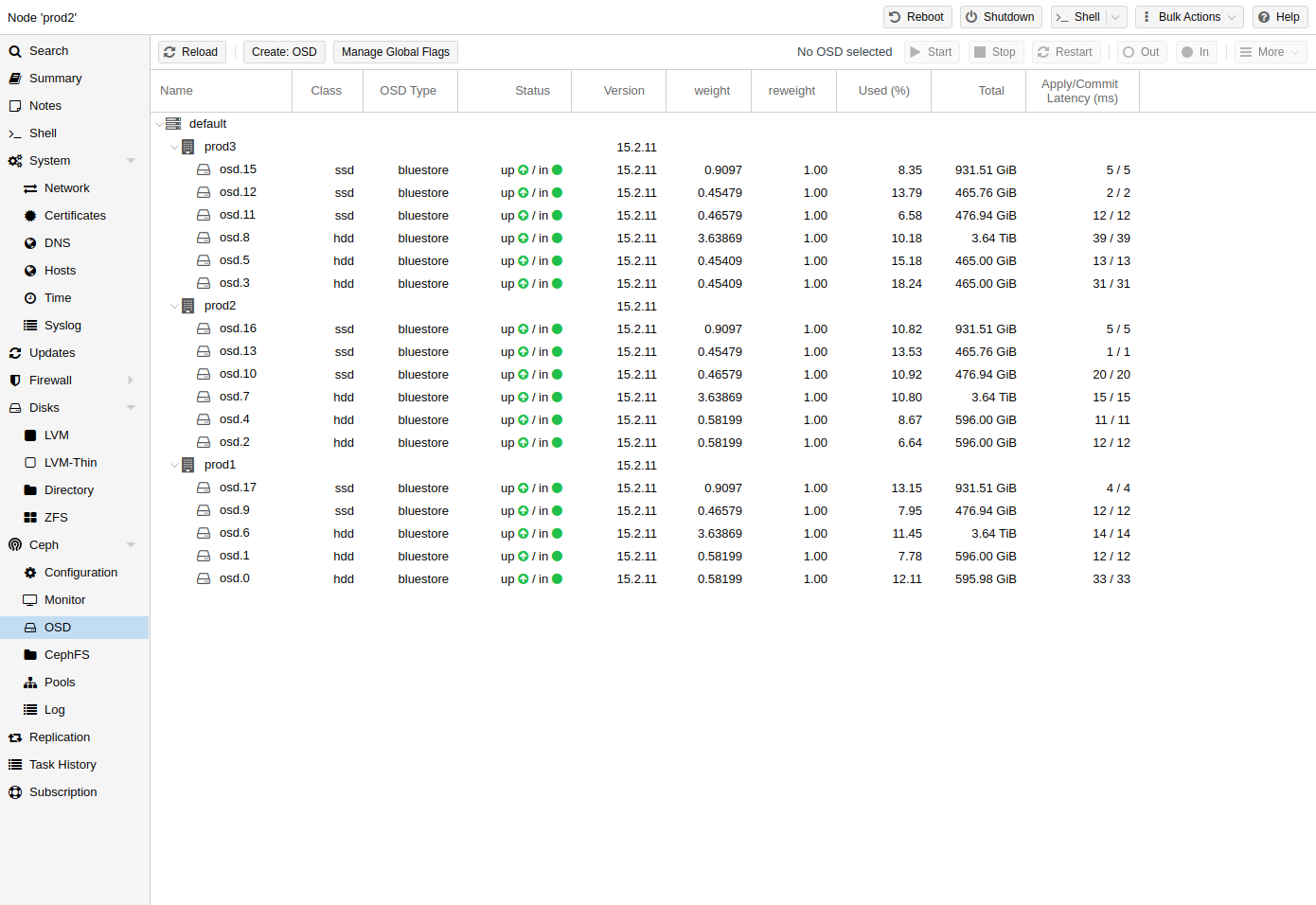
Ceph对象存储守护进程通过网络为 Ceph 存储对象。建议每个物理磁盘使用一个 OSD。
8.5.1. 创建 OSD
您可以通过 Proxmox VE Web 界面或使用pveceph通过 CLI 创建 OSD 。例如:
pveceph osd 创建 /dev/sd [ X ]
 |
我们建议 Ceph 集群至少有 3 个节点和至少 12 个 OSD,均匀分布在节点之间。 |
如果磁盘之前已被使用过(例如,用于 ZFS 或作为 OSD),您首先需要清除该使用的所有痕迹。要删除分区表、引导扇区和任何其他 OSD 剩余内容,您可以使用以下命令:
ceph-volume lvm zap /dev/sd [ X ] --destroy
|
上面的命令会破坏磁盘上的所有数据! |
从 Ceph Kraken 版本开始,引入了一种新的 Ceph OSD 存储类型,称为 Bluestore [ 20 ]。这是自 Ceph Luminous 以来创建 OSD 时的默认设置。
pveceph osd 创建 /dev/sd [ X ]
如果要为 OSD 使用单独的 DB/WAL 设备,可以通过-db_dev和-wal_dev选项指定它。如果没有单独指定,WAL 与 DB 一起放置。
pveceph osd 创建 /dev/sd [ X ] -db_dev /dev/sd [ Y ] -wal_dev /dev/sd [ Z ]
您可以分别使用-db_size和-wal_size参数直接选择它们的大小 。如果未给出,将使用以下值(按顺序):
-
来自 Ceph 配置的 bluestore_block_{db,wal}_size…
-
…数据库,osd部分
-
…数据库,全局部分
-
… 文件、osd部分
-
… 文件,全局部分
-
-
OSD 大小的 10% (DB)/1% (WAL)
|
DB 存储 BlueStore 的内部元数据,WAL 是 BlueStore 的内部日志或预写日志。建议使用快速 SSD 或 NVRAM 以获得更好的性能。 |
在 Ceph Luminous 之前,Filestore 被用作 Ceph OSD 的默认存储类型。从 Ceph Nautilus 开始,Proxmox VE 不再支持使用 pveceph创建此类 OSD 。如果您仍想创建文件存储 OSD,请直接使用 ceph-volume。
ceph-volume lvm create --filestore --data /dev/sd [ X ] --journal /dev/sd [ Y ]
8.5.2. 销毁 OSD
要通过 GUI 删除 OSD,首先在树视图中选择 Proxmox VE 节点,然后转到Ceph → OSD面板。然后选择要销毁的 OSD 并单击OUT 按钮。OSD 状态从in变为 out 后,单击STOP按钮 。最后,当状态从up变为down后, 从“更多”下拉菜单中选择“销毁” 。
要通过 CLI 删除 OSD,请运行以下命令。
ceph osd out <ID> systemctl stop ceph-osd @ <ID> 。服务
|
第一个命令指示 Ceph 不要将 OSD 包含在数据分发中。第二个命令停止 OSD 服务。直到此时,没有数据丢失。 |
以下命令会破坏 OSD。指定-cleanup选项以额外销毁分区表。
pveceph osd销毁<ID>
|
上面的命令会破坏磁盘上的所有数据! |
8.6。Ceph 池
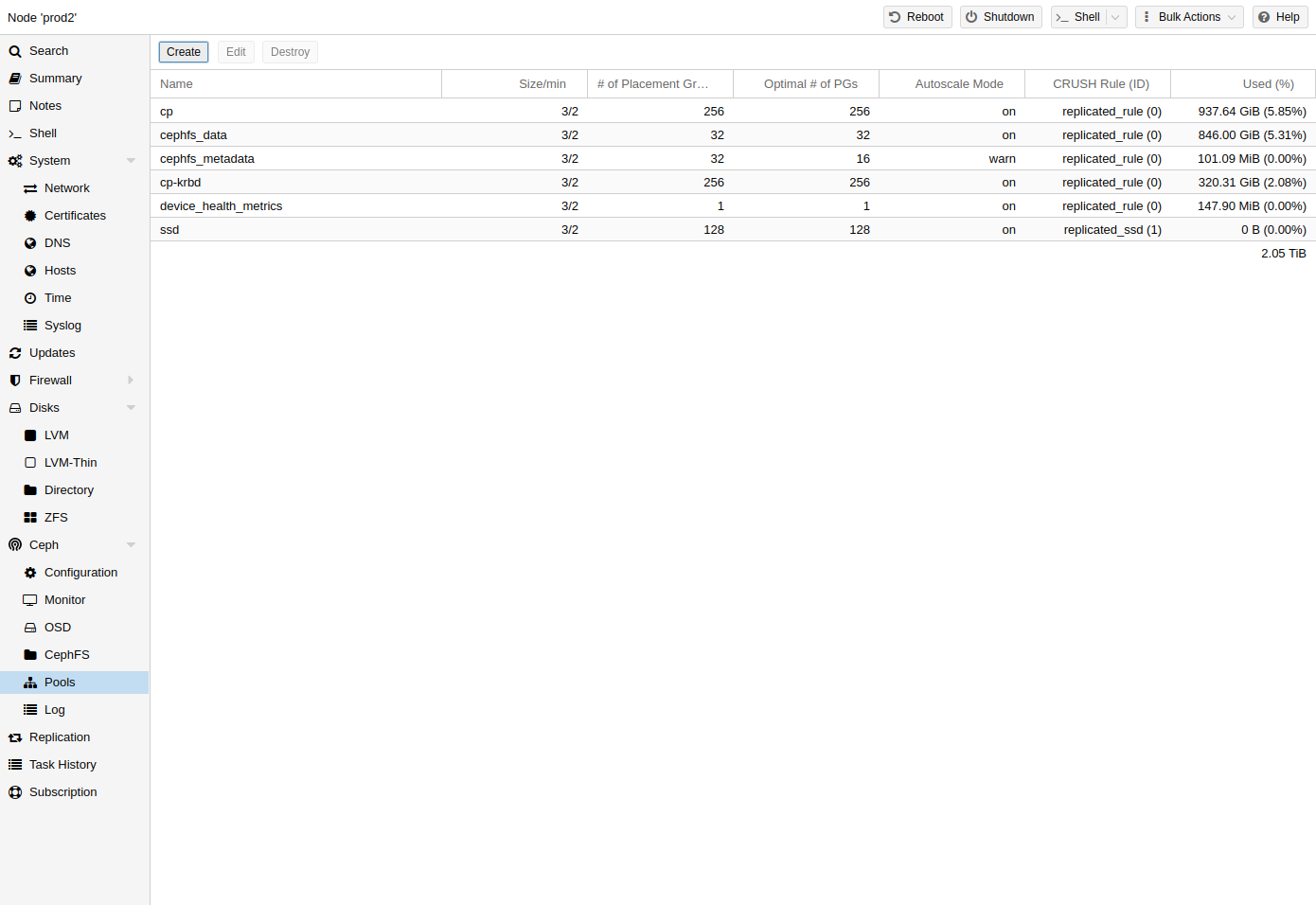
池是用于存储对象的逻辑组。它包含一个对象集合,称为放置组(PG、pg_num)。
8.6.1. 创建和编辑池
您可以从命令行或任何 Proxmox VE 主机的 Web 界面在Ceph → Pools下创建和编辑池。
当没有给出任何选项时,我们设置默认为128 个 PG,大小为 3 个副本,min_size 为 2 个副本,以确保在任何 OSD 失败时不会发生数据丢失。
|
不要将 min_size 设置为 1。min_size 为 1 的复制池允许在只有 1 个副本的对象上进行 I/O,这可能会导致数据丢失、PG 不完整或找不到对象。 |
建议您启用 PG-Autoscaler 或根据您的设置计算 PG 编号。您可以在线找到公式和 PG 计算器 [ 21 ]。从 Ceph Nautilus 开始,您可以在设置后更改 PG 的数量 [ 22 ] 。
PG 自动缩放器[ 23 ]可以在后台自动缩放池的 PG 计数。设置 目标大小或目标比率高级参数有助于 PG-Autoscaler 做出更好的决策。
pveceph pool create <池名称> --add_storages
|
如果您还想自动为池定义存储,请在 Web 界面中选中“添加为存储”复选框,或在创建池时使用命令行选项–add_storages。 |
池选项
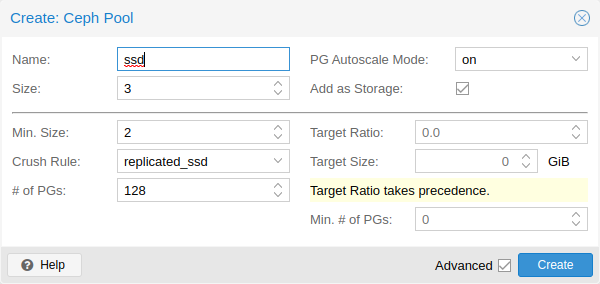
以下选项在创建池时可用,部分在编辑池时也可用。
- 姓名
-
池的名称。这必须是唯一的并且之后不能更改。
- 尺寸
-
每个对象的副本数。Ceph 总是尝试拥有一个对象的这么多副本。默认值:3。
- PG 自动缩放模式
-
池的 自动PG缩放模式[ 23 ] 。如果设置为warn,当池的 PG 计数非最佳时,它会生成警告消息。默认值:警告。
- 添加为存储
-
使用新池配置虚拟机或容器存储。默认值:true(仅在创建时可见)。
- 分钟。尺寸
-
每个对象的最小副本数。如果 PG 的副本数量少于此数量,Ceph 将拒绝池上的 I/O。默认值:2。
- 粉碎规则
-
用于映射集群中对象放置的规则。这些规则定义了数据在集群中的放置方式。有关基于设备的规则的信息, 请参阅 Ceph CRUSH 和设备类。
- PG 数量
-
池在开始时应具有的归置组[ 22 ] 数量。默认值:128。
- 目标比率
-
池中预期数据的比率。PG 自动缩放器使用相对于其他比率集的比率。如果两者都设置了,则它优先于目标大小。
- 目标尺寸
-
池中预期的估计数据量。PG 自动缩放器使用此大小来估计最佳 PG 计数。
- 分钟。PG 数量
-
归置组的最小数量。此设置用于微调该池的 PG 计数下限。PG 自动缩放器不会合并低于此阈值的 PG。
有关 Ceph 池处理的更多信息可以在 Ceph 池操作[ 24 ]手册中找到 。
8.6.2. 纠删码池
纠删码 (EC) 是“前向纠错”代码的一种形式,允许从一定量的数据丢失中恢复。与复制池相比,纠删码池可以提供更多的可用空间,但这样做是以性能为代价的。
为了进行比较:在经典的复制池中,存储数据的多个副本(大小),而在纠删码池中,数据被分割成k 个数据块,并附加m 个编码(检查)块。如果数据块丢失,这些编码块可用于重新创建数据。
编码块的数量m定义了在不丢失任何数据的情况下可以丢失多少个 OSD。存储的对象总数为k + m。
创建EC池
可以使用pveceph CLI 工具创建纠删码 (EC) 池。规划 EC 池需要考虑到这样一个事实:它们的工作方式与复制池不同。
EC池的默认min_size取决于m参数。如果m = 1,则 EC 池的min_size将为k。如果 m > 1 ,则 min_size将为k + 1。Ceph 文档建议保守的min_size为k + 2 [ 25 ]。
如果可用的 OSD 少于min_size,则池中的任何 IO 都将被阻止,直到再次有足够的 OSD 可用。
|
规划纠删码池时,请留意min_size,因为它定义了需要可用的 OSD 数量。否则IO会被阻塞。 |
例如,k = 2且m = 1的 EC 池的size = 3、 min_size = 2,并且在一个 OSD 发生故障时仍将保持运行。如果池配置为k = 2、m = 2,则它将具有size = 4和min_size = 3 ,并且在丢失一个 OSD 时保持运行状态。
要创建新的 EC 池,请运行以下命令:
pveceph pool create <池名称> --erasure-coding k = 2 , m = 1
可选参数为failure-domain和device-class。如果您需要更改池使用的任何 EC 配置文件设置,则必须使用新配置文件创建新池。
这将创建一个新的 EC 池以及所需的复制池来存储 RBD omap 和其他元数据。最后,将有一个<pool name>-data和 <pool name>-metada池。默认行为也是创建匹配的存储配置。如果不需要该行为,您可以通过提供–add_storages 0参数来禁用它。手动配置存储配置时,请记住需要设置数据池参数。只有这样,EC池才会被用来存储数据对象。例如:
|
可选参数–size、–min_size和–crush_rule将用于复制元数据池,但不适用于纠删码数据池。如果您需要更改数据池上的min_size ,可以稍后进行。纠删码池上的 size和rush_rule参数无法更改。 |
如果需要进一步自定义 EC 配置文件,可以直接使用 Ceph 工具创建它[ 26 ],并通过profile参数指定要使用的配置文件。
例如:
pveceph pool create <池名称> --erasure-coding profile =<配置文件名称>
添加 EC 池作为存储
您可以将现有的 EC 池添加为 Proxmox VE 的存储。它的工作方式与添加RBD池相同,但需要额外的数据池选项。
pvesm add rbd <存储名称> --pool <复制池> --data- pool <ec-pool>
|
不要忘记为任何不由本地 Proxmox VE 集群管理的外部 Ceph 集群添加keyring和monhost选项。 |
8.6.3. 摧毁水池
要通过 GUI 销毁池,请在树视图中选择一个节点,然后转到 Ceph → 池面板。选择要销毁的池并单击“销毁” 按钮。要确认池的销毁,需要输入池名称。
运行以下命令来销毁池。指定-remove_storages以同时删除关联的存储。
pveceph池销毁<名称>
|
池删除在后台运行,可能需要一些时间。您会注意到在此过程中集群中的数据使用量不断减少。 |
8.6.4. PG自动定标器
PG 自动缩放器允许集群考虑每个池中存储的(预期)数据量并自动选择适当的 pg_num 值。它自 Ceph Nautilus 起可用。
您可能需要激活 PG 自动定标器模块才能使调整生效。
ceph mgr模块启用pg_autoscaler
自动缩放程序是按池配置的,并具有以下模式:
| 警告 |
如果建议的pg_num值与当前值相差太大, 则会发出健康警告。 |
| 在 |
pg_num会自动调整,无需任何手动交互。 |
| 离开 |
不会进行自动pg_num调整,如果 PG 计数不是最佳,也不会发出警告。 |
可以使用 target_size、target_size_ratio和pg_num_min选项调整缩放因子以方便将来的数据存储。
|
默认情况下,如果池的 PG 计数相差 3 倍,自动缩放程序会考虑调整该计数。这将导致数据放置发生相当大的变化,并可能会给集群带来高负载。 |
您可以在 Ceph 的博客 – New in Nautilus: PG merging and autotuning上找到有关 PG 自动缩放器的更深入介绍 。
8.7. Ceph CRUSH 和设备类别
[ 27 ](可扩展 哈希下的受控复制)算法是Ceph的基础。
CRUSH 计算存储和检索数据的位置。这样做的优点是不需要中央索引服务。CRUSH 使用 OSD、存储桶(设备位置)和池规则集(数据复制)的映射进行工作。
|
更多信息可以在 Ceph 文档的 CRUSH 映射部分下找到[ 28 ]。 |
可以更改此映射以反映不同的复制层次结构。对象副本可以被分离(例如,故障域),同时保持期望的分布。
常见的配置是为不同的 Ceph 池使用不同类别的磁盘。因此,Ceph 引入了带有 luminous 的设备类,以满足轻松生成规则集的需求。
设备类可以在ceph osd 树输出中看到。这些类代表它们自己的根存储桶,可以使用以下命令查看。
ceph osd 粉碎树 --show-shadow
上述命令的输出示例:
ID 类别权重类型名称 - 16 nvme 2.18307 root 默认~ nvme - 13 nvme 0.72769 主机 sumi1 ~ nvme 12 nvme 0.72769 osd 。12 - 14 nvme 0.72769 主机 sumi2 ~ nvme 13 nvme 0.72769 osd 。13 - 15 nvme 0.72769 主机 sumi3 ~ nvme 14 nvme 0.72769 osd 。14 - 1 7.70544 root 默认 - 3 2.56848 主机 sumi1 12 nvme 0.72769 osd 。12 - 5 2.56848 主机 sumi2 13 nvme 0.72769 osd 。13 - 7 2.56848 主机 sumi3 14 nvme 0.72769 osd 。14
要指示池仅在特定设备类上分发对象,您首先需要为设备类创建规则集:
ceph osdrush规则create-replicated <规则名称> <根> <故障域> <类>
|
<规则名称> |
规则名称,用于连接池(在 GUI 和 CLI 中看到) |
|
<根> |
它应该属于哪个粉碎根(默认 Ceph 根“默认”) |
|
<故障域> |
对象应分布在哪个故障域(通常是主机) |
|
<类> |
使用什么类型的 OSD 后备存储(例如,nvme、ssd、hdd) |
一旦规则位于 CRUSH 映射中,您就可以告诉池使用该规则集。
ceph osd 池集 <池名称> rush_rule <规则名称>
|
如果池中已经包含对象,则必须相应地移动这些对象。根据您的设置,这可能会对您的集群产生很大的性能影响。作为替代方案,您可以创建新池并单独移动磁盘。 |
8.8. Ceph客户端
按照前面部分的设置,您可以将 Proxmox VE 配置为使用此类池来存储 VM 和容器映像。只需使用 GUI 添加新的 RBD存储(请参阅 Ceph RADOS 块设备 (RBD)部分)。
您还需要将密钥环复制到外部 Ceph 集群的预定义位置。如果 Ceph 安装在 Proxmox 节点本身上,那么这将自动完成。
|
文件名必须是<storage_id> + `.keyring,其中<storage_id>是/etc/pve/storage.cfg中rbd:之后的表达式。在以下示例中, my-ceph-storage是<storage_id>: |
mkdir /etc/pve/priv/ceph cp /etc/ceph/ceph 。客户。管理员。密钥环 /etc/pve/priv/ceph/my-ceph-storage 。钥匙圈
8.9。CephFS
Ceph 还提供了一个文件系统,它与 RADOS 块设备运行在同一对象存储之上。元数据服务器( MDS ) 用于将 RADOS 支持的对象映射到文件和目录,从而允许 Ceph 提供符合 POSIX 的复制文件系统。这使您可以轻松配置集群、高可用、共享文件系统。Ceph 的元数据服务器保证文件均匀分布在整个 Ceph 集群上。因此,即使是高负载的情况也不会压垮单个主机,这可能是传统共享文件系统方法(例如NFS)的问题。
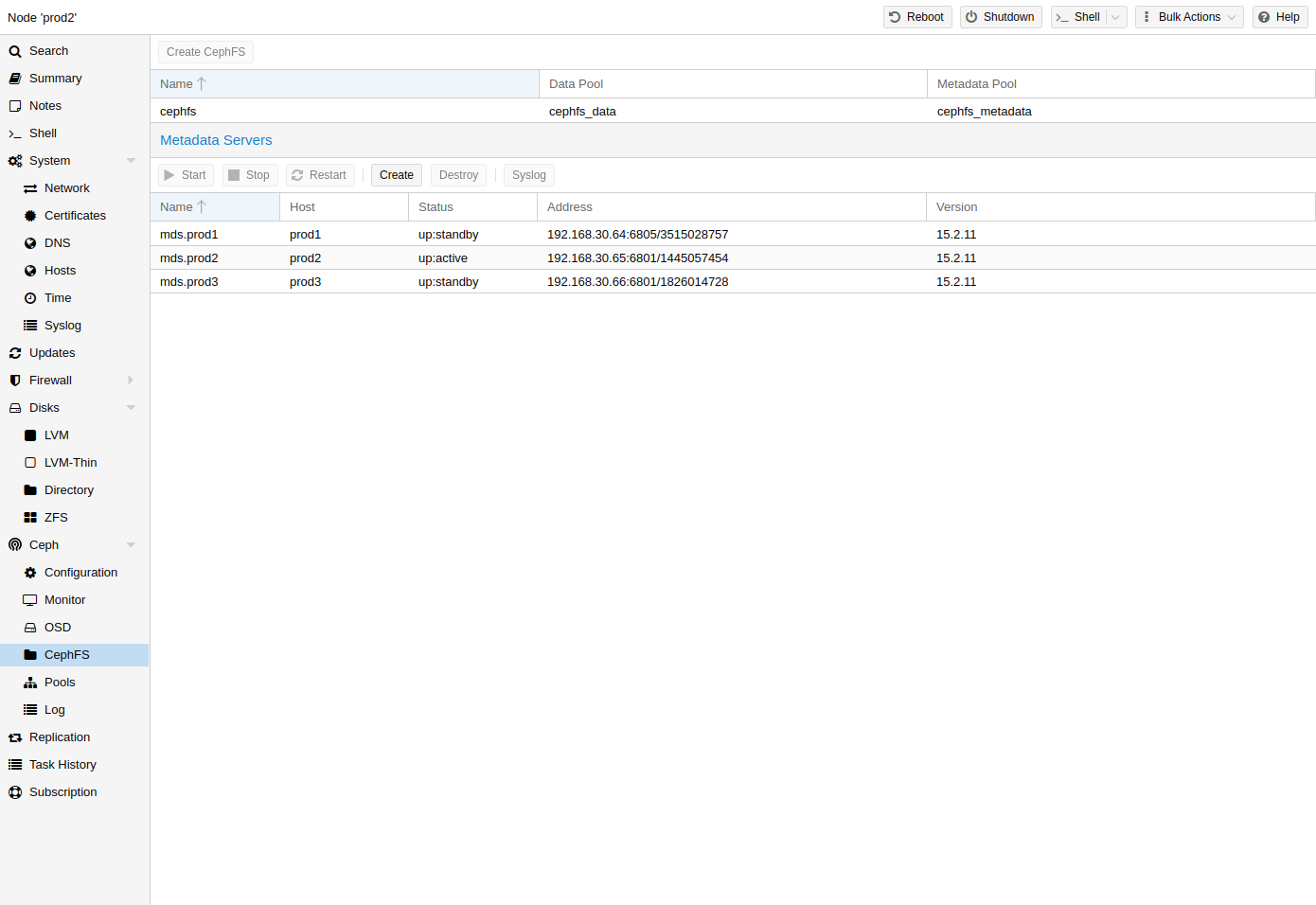
Proxmox VE既支持创建超融合CephFS,也支持使用现有的 CephFS作为存储来保存备份、ISO文件和容器模板。
8.9.1. 元数据服务器(MDS)
CephFS 至少需要配置并运行一台元数据服务器才能正常运行。您可以通过 Proxmox VE Web GUI 的Node -> CephFS面板或从命令行创建 MDS:
pveceph mds 创建
一个集群中可以创建多个元数据服务器,但在默认设置下,一次只能有一个处于活动状态。如果 MDS 或其节点变得无响应(或崩溃),另一个备用MDS 将提升为活动状态。您可以通过在创建时使用hotstandby参数选项来加快主用和备用 MDS 之间的切换,或者如果您已经创建了它,则可以设置/添加:
MDS 待机重播 = true
在/etc/pve/ceph.conf的相应 MDS 部分中。启用此功能后,指定的 MDS 将保持在热状态,轮询活动状态,以便在出现任何问题时可以更快地接管。
|
这种主动轮询将对您的系统和主动MDS产生额外的性能影响。 |
从 Luminous (12.2.x) 开始,您可以同时运行多个活动元数据服务器,但这通常仅在您有大量并行运行的客户端时才有用。否则,MDS很少成为系统中的瓶颈。如果您想进行设置,请参阅 Ceph 文档。 [ 29 ]
8.9.2. 创建 CephFS
通过 Proxmox VE 与 CephFS 的集成,您可以使用 Web 界面、CLI 或外部 API 接口轻松创建 CephFS。要使其发挥作用,需要一些先决条件:
-
安装 Ceph 软件包– 如果之前已经完成此操作,您可能需要在最新的系统上重新运行它,以确保安装所有与 CephFS 相关的软件包。
完成后,您可以通过 Web GUI 的Node -> CephFS面板或命令行工具pveceph简单地创建 CephFS ,例如:
pveceph fs 创建 --pg_num 128 --add-storage
这将创建一个名为cephfs的 CephFS ,使用名为 cephfs_data的数据池(具有128 个置放组)和一个名为 cephfs_metadata的元数据池(包含四分之一的数据池置放组 ( 32 ))。请查看Proxmox VE 管理的 Ceph 池一章或访问 Ceph 文档,以获取有关适合您的设置的适当归置组编号 ( pg_num )的更多信息[ 22 ]。此外,成功创建后,–add-storage参数会将 CephFS 添加到 Proxmox VE 存储配置中。
8.9.3。销毁CephFS
|
销毁 CephFS 将导致其所有数据无法使用。这不能被撤消! |
要完全、优雅地删除 CephFS,需要执行以下步骤:
-
断开每个非 Proxmox VE 客户端的连接(例如卸载来宾中的 CephFS)。
-
禁用所有相关的 CephFS Proxmox VE 存储条目(以防止其自动挂载)。
-
从要销毁的 CephFS 上的来宾(例如 ISO)中删除所有已使用的资源。
-
手动卸载所有集群节点上的 CephFS 存储
umount /mnt/pve/<存储名称>
其中<STORAGE-NAME>是 Proxmox VE 中 CephFS 存储的名称。
-
现在,通过停止或销毁元数据服务器( MDS ) 来确保没有为该 CephFS 运行它们。这可以通过 Web 界面或通过命令行界面来完成,对于后者,您将发出以下命令:
pveceph stop --service mds.NAME
阻止他们,或者
pveceph mds 销毁 NAME
摧毁他们。
请注意,当活动MDS停止或删除时,备用服务器将自动升级为活动服务器,因此最好首先停止所有备用服务器。
-
现在您可以使用以下命令销毁 CephFS
pveceph fs destroy NAME --remove-storages --remove-pools
这将自动销毁底层 Ceph 池并从 pve 配置中删除存储。
完成这些步骤后,CephFS 应该被完全删除,如果您还有其他 CephFS 实例,则可以再次启动已停止的元数据服务器以充当备用服务器。
8.10。Ceph维护
8.10.1. 更换 OSD
Ceph 中最常见的维护任务之一是更换 OSD 磁盘。如果磁盘已处于故障状态,则您可以继续执行销毁 OSD中的步骤。如果可能的话,Ceph 将在剩余的 OSD 上重新创建这些副本。一旦检测到 OSD 故障或主动停止 OSD,就会开始重新平衡。
|
使用池的默认大小/最小大小 (3/2),仅当“size + 1”节点可用时才开始恢复。原因是 Ceph 对象平衡器CRUSH默认将完整节点作为“故障域”。 |
要从 GUI 更换正常运行的磁盘,请执行销毁 OSD中的步骤 。唯一的补充是等待集群显示HEALTH_OK,然后再停止 OSD 来销毁它。
在命令行上,使用以下命令:
ceph osd 输出 osd。<id>
您可以使用以下命令检查是否可以安全删除 OSD。
ceph osd 可安全销毁 osd。<id>
一旦上述检查告诉您可以安全删除 OSD,您可以继续执行以下命令:
systemctl stop ceph-osd@<id>.service pveceph osd destroy <id>
将旧磁盘替换为新磁盘,并使用创建 OSD中所述的相同过程。
8.10.2. 修剪/丢弃
在虚拟机和容器上定期运行fstrim(丢弃)是一种很好的做法。这会释放文件系统不再使用的数据块。它减少了数据使用和资源负载。大多数现代操作系统都会定期向其磁盘发出此类丢弃命令。您只需确保虚拟机启用磁盘丢弃选项即可。
8.10.3. 磨砂膏和深层磨砂膏
Ceph 通过清理归置组来确保数据完整性。Ceph 检查 PG 中每个对象的健康状况。清理有两种形式,每日廉价元数据检查和每周深度数据检查。每周深度清理会读取对象并使用校验和来确保数据完整性。 如果正在运行的清理干扰了业务(性能)需求,您可以调整执行清理[ 30 ]的时间。
8.11。Ceph 监控和故障排除
通过使用 Ceph 工具或通过 Proxmox VE API访问状态,从一开始就持续监控 Ceph 部署的运行状况非常重要。
以下 Ceph 命令可用于查看集群是否健康(HEALTH_OK),是否有警告(HEALTH_WARN),甚至错误(HEALTH_ERR)。如果集群处于不健康状态,下面的状态命令还将为您提供当前事件和要采取的操作的概述。
# 单次输出 pve# ceph -s # 连续输出状态变化(按CTRL+C停止) pve# ceph -w
为了获得更详细的视图,每个 Ceph 服务在/var/log/ceph/下都有一个日志文件 。如果需要更多详细信息,可以调整日志级别[ 31 ]。
您可以 在官方网站上找到有关对 Ceph 集群进行故障排除的更多信息[ 32 ] 。